In recent times, automatic text-to-3D content creation has made significant progress, driven by the development of pretrained 2D diffusion models. Existing text-to-3D methods typically optimize the 3D representation to ensure that the rendered image aligns well with the given text, as evaluated by the pretrained 2D diffusion model. Nevertheless, a substantial domain gap exists between 2D images and 3D assets, primarily attributed to variations in camera-related attributes and the exclusive presence of foreground objects. Consequently, employing 2D diffusion models directly for optimizing 3D representations may lead to suboptimal outcomes. To address this issue, we present X-Dreamer, a novel approach for high-quality text-to-3D content creation that effectively bridges the gap between text-to-2D and text-to-3D synthesis. The key components of X-Dreamer are two innovative designs: Camera-Guided Low-Rank Adaptation (CG-LoRA) and Attention-Mask Alignment (AMA) Loss. CG-LoRA dynamically incorporates camera information into the pretrained diffusion models by employing camera-dependent generation for trainable parameters. This integration enhances the alignment between the generated 3D assets and the camera’s perspective. AMA loss guides the attention map of the pretrained diffusion model using the binary mask of the 3D objects, prioritizing the creation of the foreground object. This module ensures that the model focuses on generating accurate and detailed foreground objects. Extensive evaluations demonstrate the effectiveness of our proposed method compared to existing text-to-3D approaches.
We've crafted a succinct video to enhance your comprehension of our work.
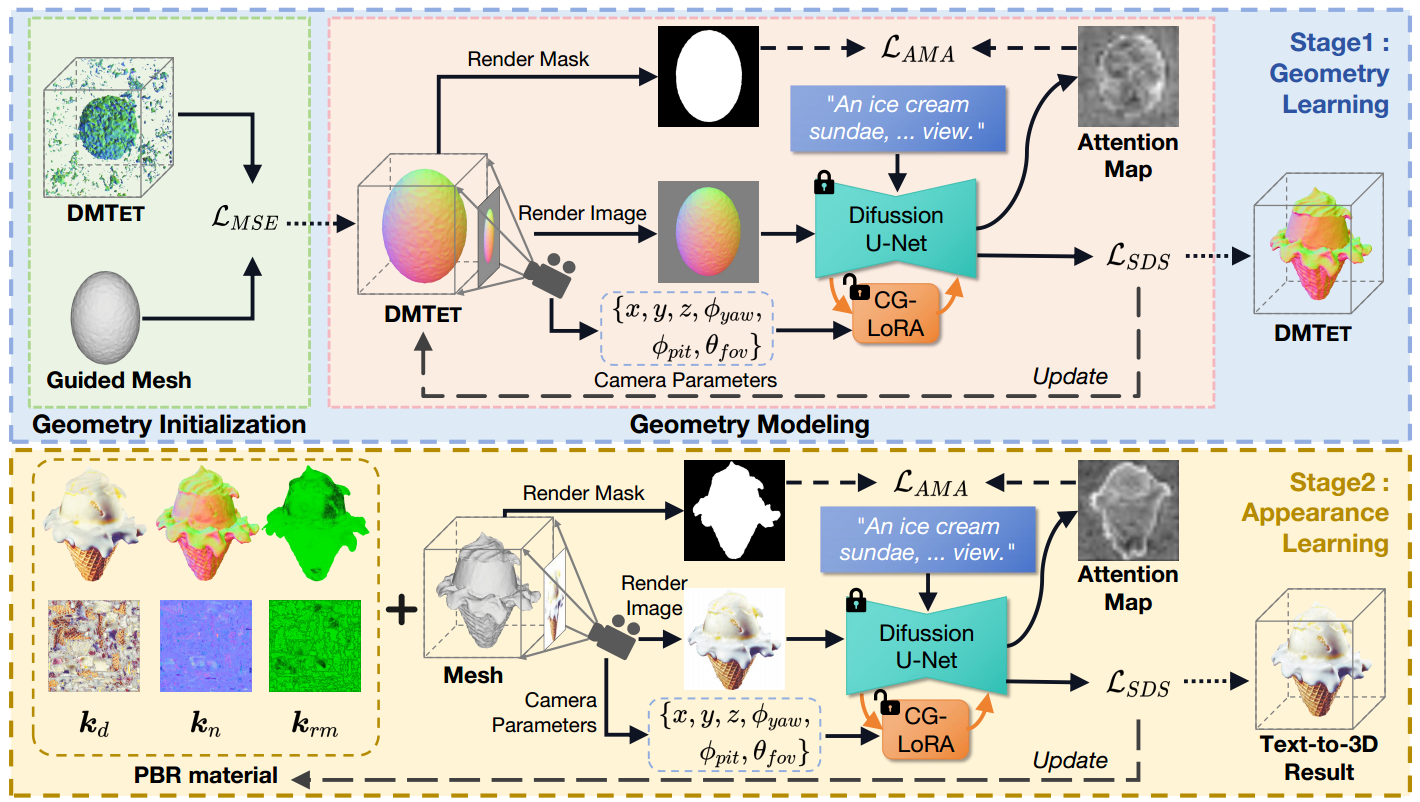
Overview of the proposed X-Dreamer, which consists of two main stages: geometry learning and appearance learning. For geometry learning, we employ DMTET as the 3D representation and initialize it with a 3D ellipsoid using the mean squared error (MSE) loss. Subsequently, we optimize DMTET and CG-LoRA using the Score Distillation Sampling (SDS) loss and our proposed Attention-Mask Alignment (AMA) loss to ensure the alignment between the 3D representation and the input text prompt. For appearance learning, we leverage bidirectional reflectance distribution function (BRDF) modeling. Specifically, we utilize an MLP with trainable parameters to predict surface materials. Similar to the geometry learning stage, we optimize the trainable parameters of MLP and CG-LoRA using the SDS loss and the AMA loss to achieve alignment between the 3D representation and the text prompt.
We conduct the experiments using four Nvidia RTX 3090 GPUs and the PyTorch library. To calculate the SDS loss, we utilize the Stable Diffusion implemented by Hugging Face Diffusers. For the DMTET and material encoder, we implement them as a two-layer MLP and a single-layer MLP, respectively, with a hidden dimension of 32. We optimize X-Dreamer for 2000 iterations for geometry learning and 1000 iterations for appearance learning.
We present representative results of X-Dreamer for text-to-3D generation, utilizing an ellipsoid as the initial geometry.
 |
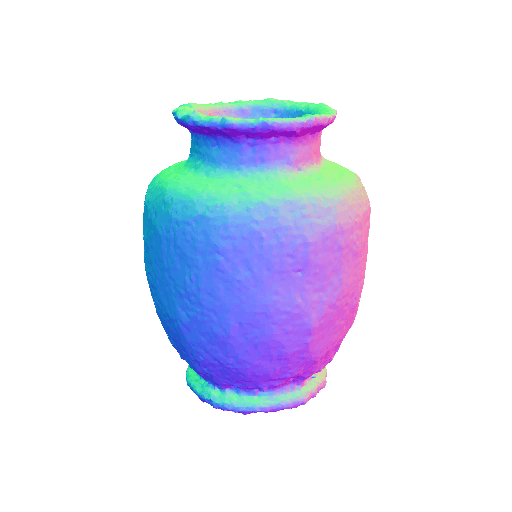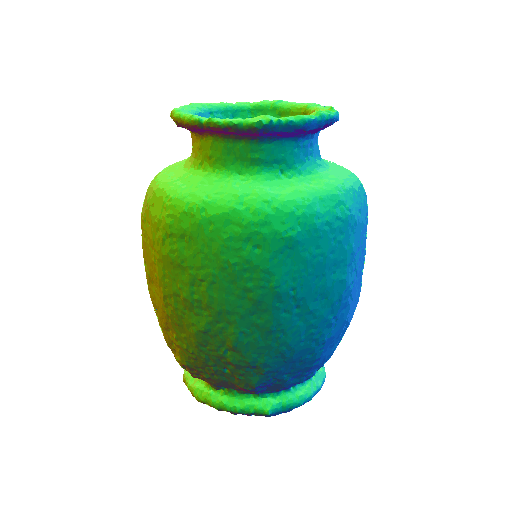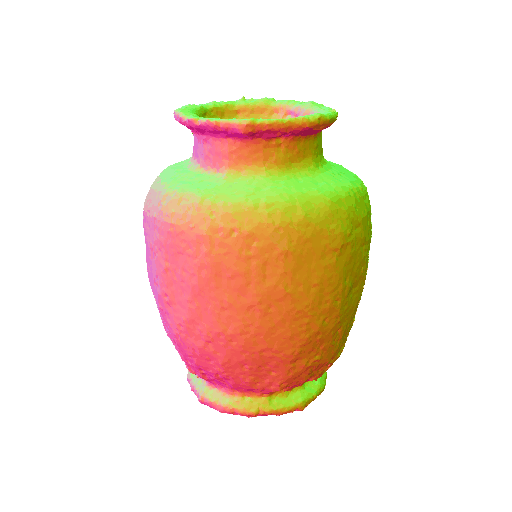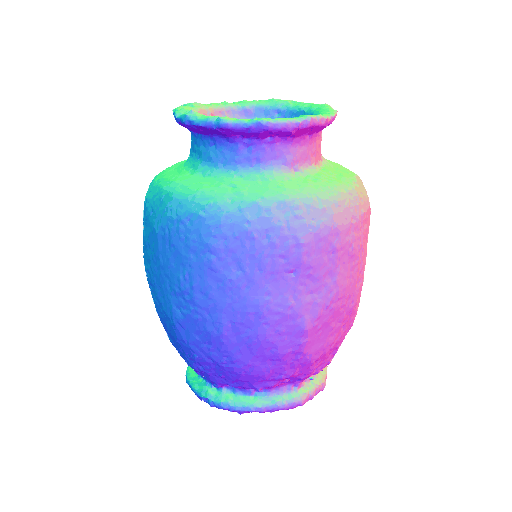 |
 |
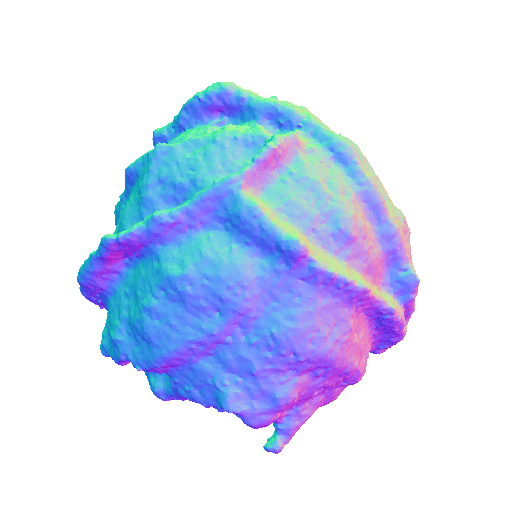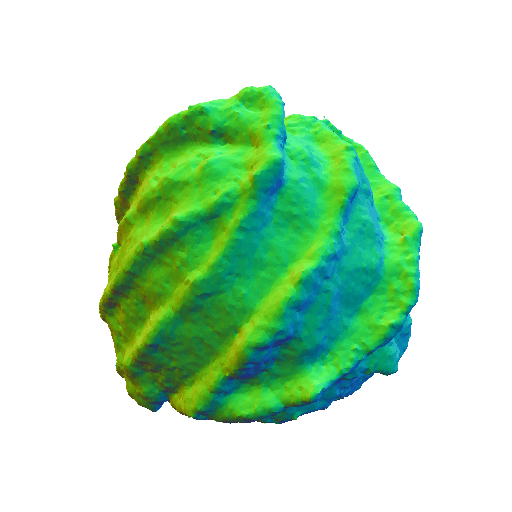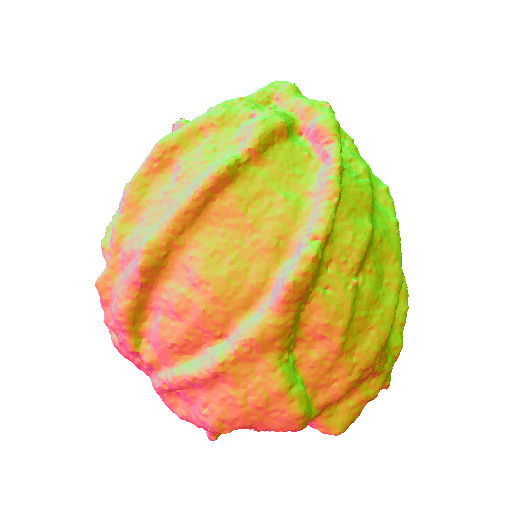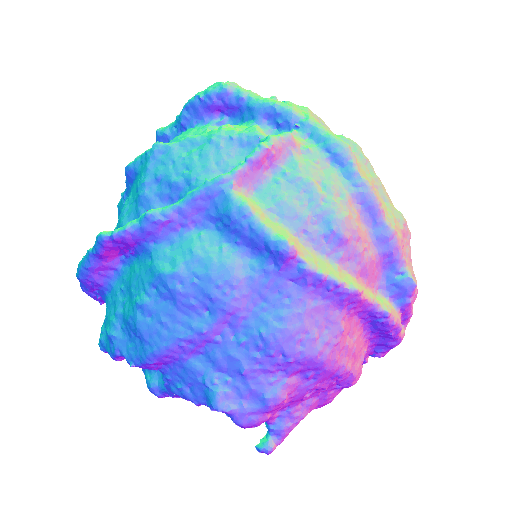 |
| A DSLR photo of a blue and white porcelain vase, highly detailed, 8K, HD. | A cabbage, highly detailed. | ||
 |
 |
 |
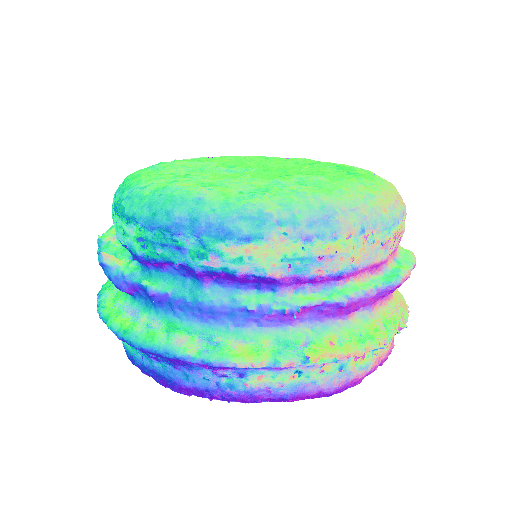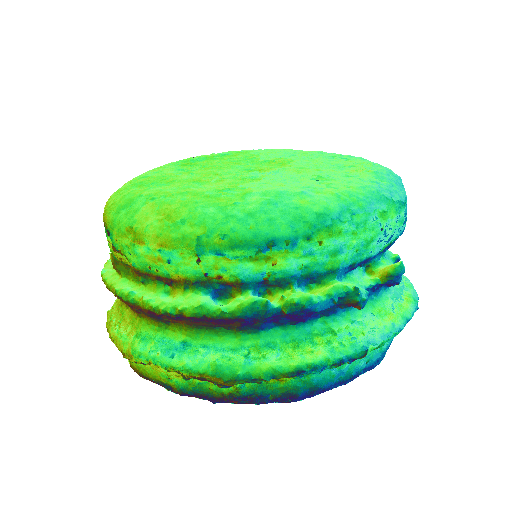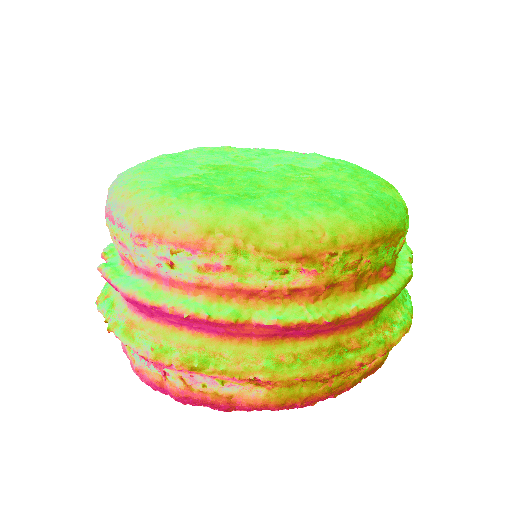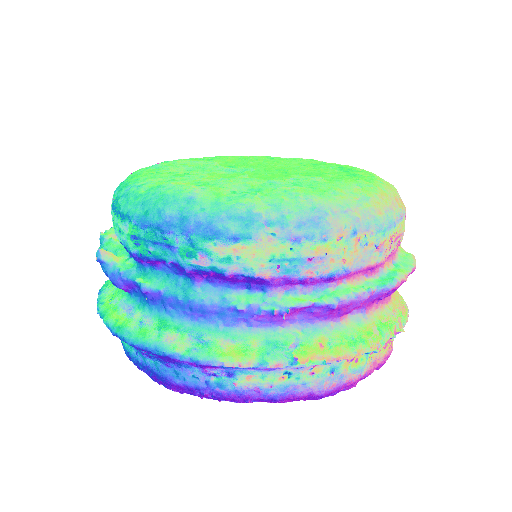 |
| A chocolate cupcake, highly detailed. | A DSLR photo of a macaron, 8K, HD, high resolution. | ||
 |
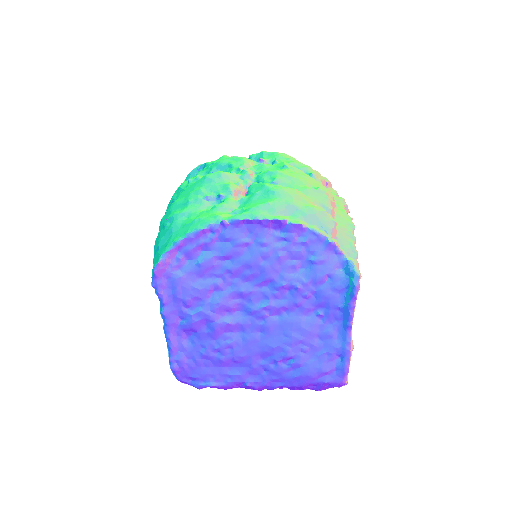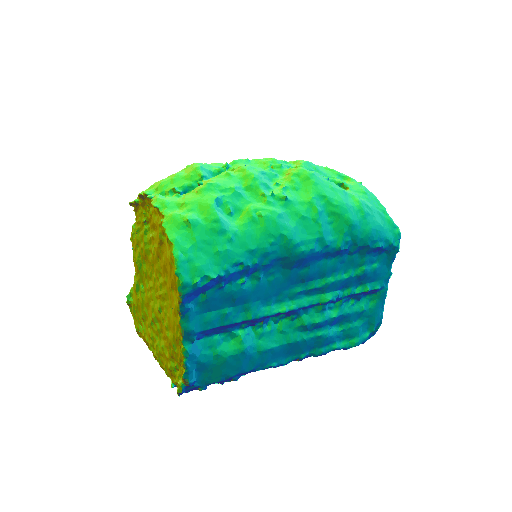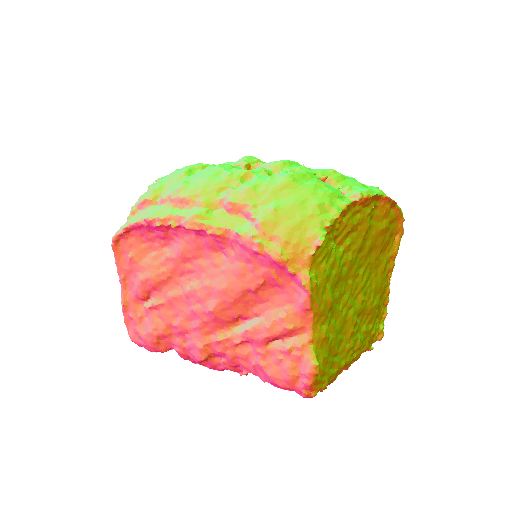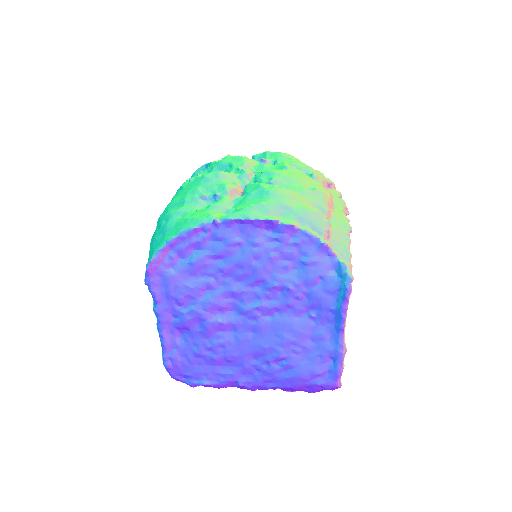
|  |
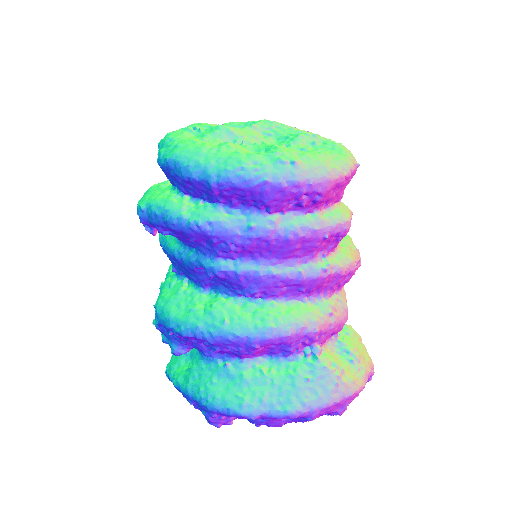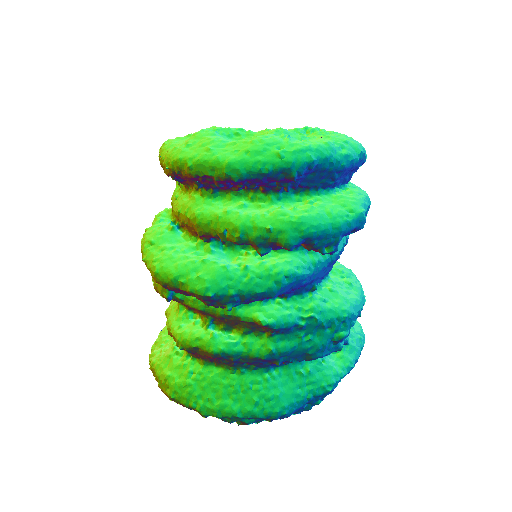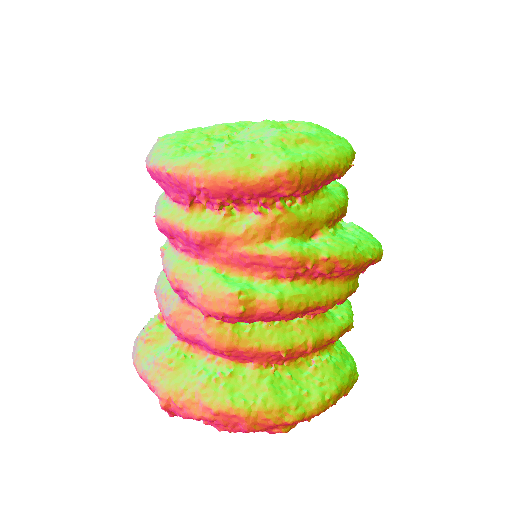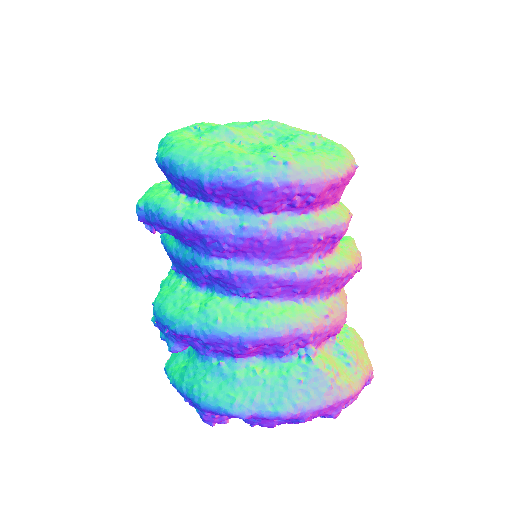 |
| A sliced loaf of fresh bread. | A plate piled high with chocolate chip cookies. | ||
 |
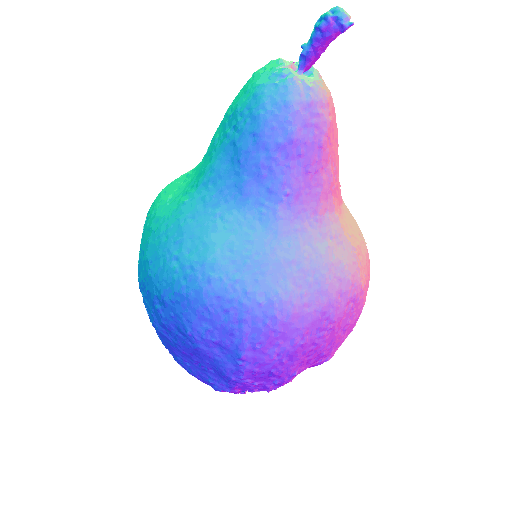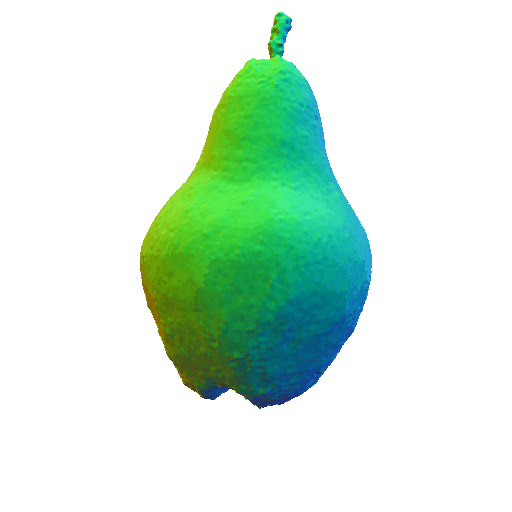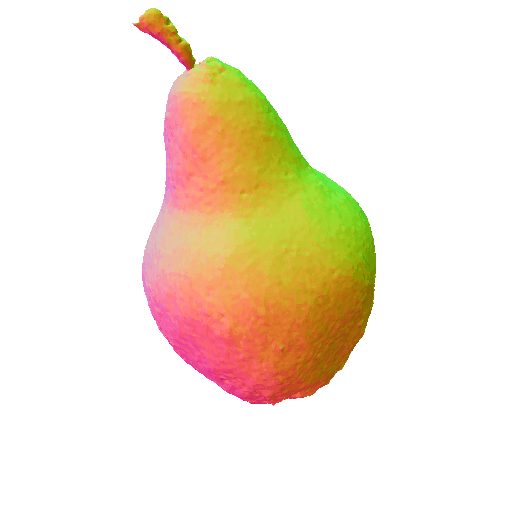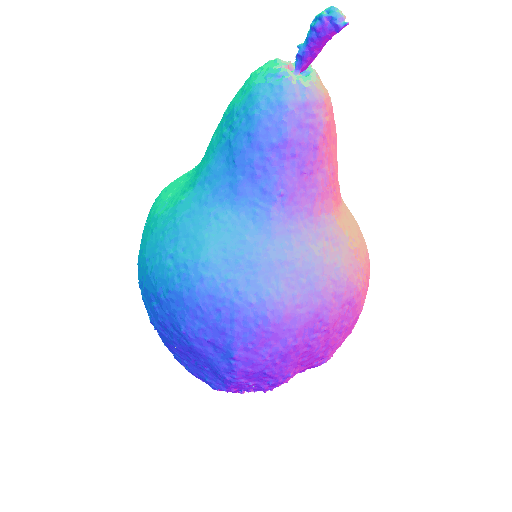 |
 |
 |
| A DSLR photo of a pear, highly detailed, 8K, HD. | A rocket. | ||
 |
 |
 |
 |
| A hamburger. | A DSLR photo of a corn, highly detailed, 8K, HD. | ||
X-Dreamer also supports text-based mesh geometry editing and is capable of delivering excellent results.

|
 |
 |
| A beautifully carved wooden queen chess piece.
|
||

|
 |
 |
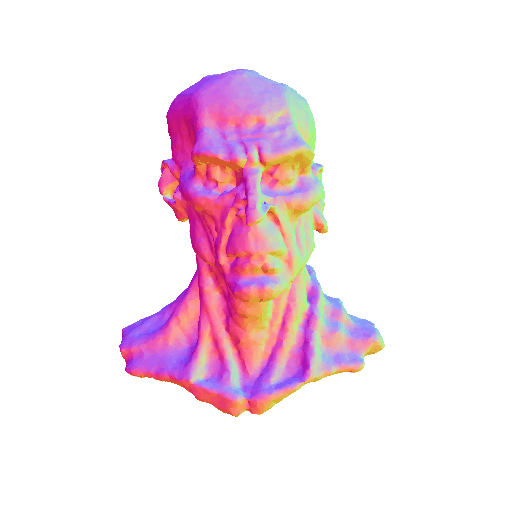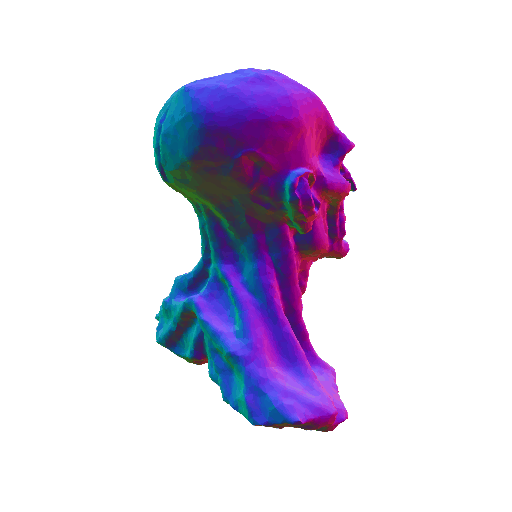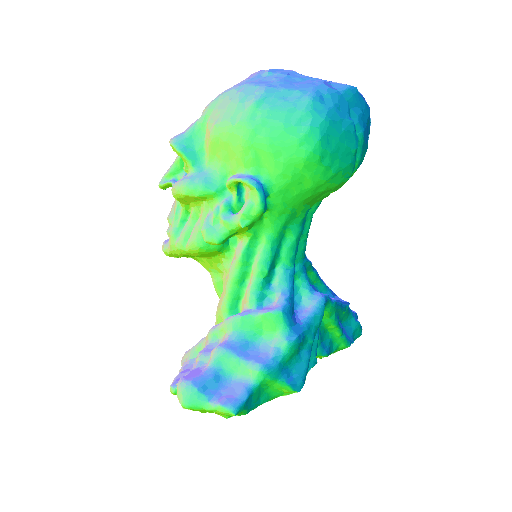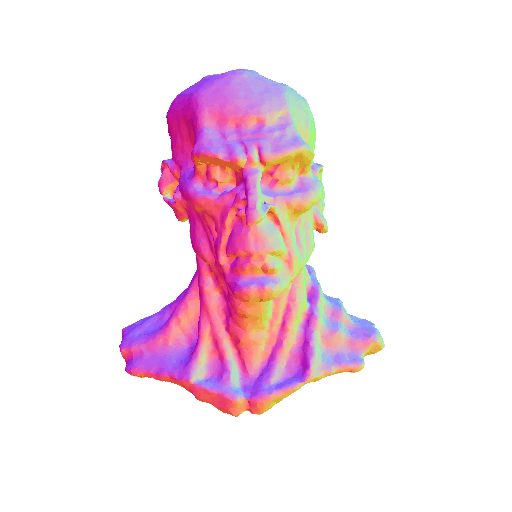
| Barack Obama's head. | ||
We demonstrate how swapping the HDR environment map results in diverse lighting, thereby creating various reflective effects on the generated 3D assets in X-Dreamer.
| Environment map | ||||||||
 |
 |
 |
|
 |
|
 |
|
 |
|
|
|
|
|||||
 |
|
 |
|
 |
|
 |
|
 |
| A DSLR photo of a brown cowboy hat. | ||||||||
 |
|
 |
|
 |
|
 |
|
 |
| Messi's head, highly detailed, 8K, HD. | ||||||||
 |
|
 |
|
 |
|
 |
|
 |
| A DSLR photo of a fox, highly detailed. | ||||||||
 |
|
 |
|
 |
|
 |
|
 |
| A DSLR photo of red rose, highly detailed, 8K, HD. | ||||||||
 |
|
 |
|
 |
|
 |
|
 |
| A marble bust of a mouse. | ||||||||
 |
|
 |
|
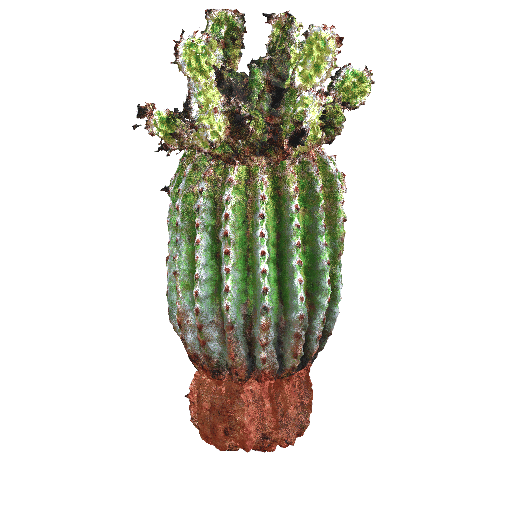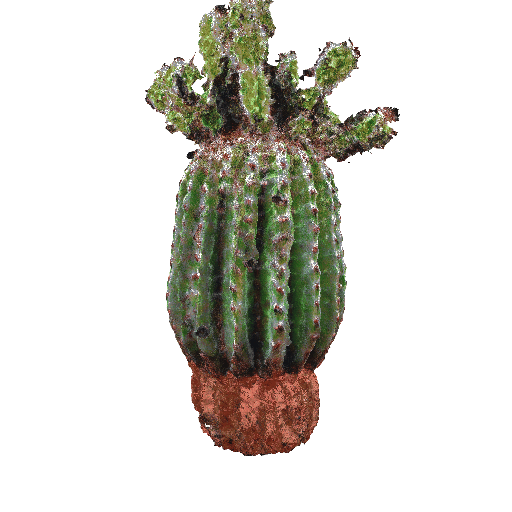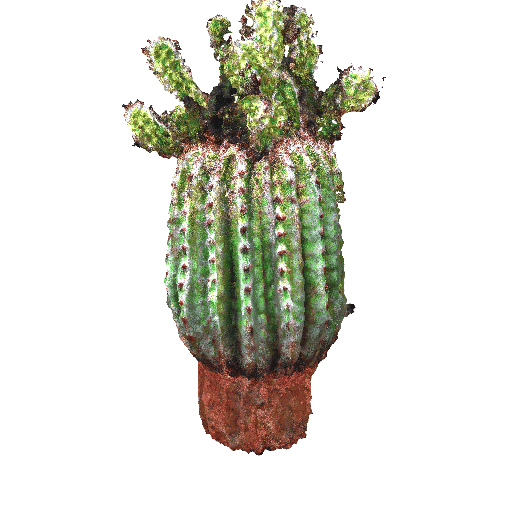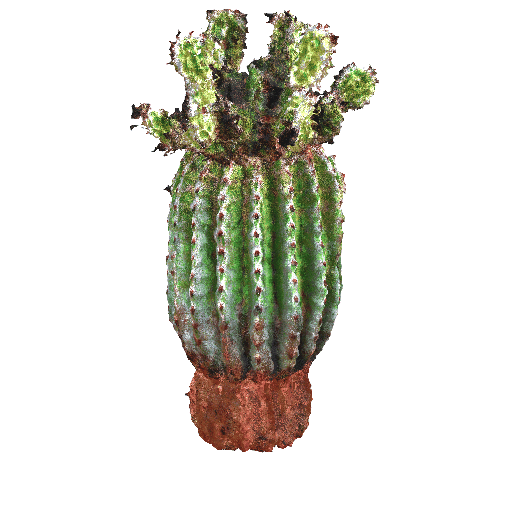 |
|
 |
|
 |
| A small saguaro cactus planted in a clay pot. | ||||||||
 |
|
 |
|
 |
|
 |
|
 |
| A DSLR photo of a vase, highly detailed, 8K, HD. | ||||||||
We demonstrate the editing process of the geometry and appearance of 3D assets in X-Dreamer using an ellipsoid and coarse-grained guided meshes as geometric shapes for initialization, respectively.
| From an ellipsoid | From coarse-grained guided meshes | ||
| A DSLR photo of a blue and white porcelain vase, highly detailed, 8K, HD. | A marble bust of an angel, 3D model, high resolution. | ||
| A stack of pancakes covered in maple syrup. | A DSLR photo of the Terracotta Army, 3D model, high resolution. | ||
We compared X-Dreamer with four state-of-the-art (SOTA) methods: DreamFusion, Magic3D, Fantasia3D, and ProlificDreamer. The results are shown below:
| DreamFusion | Magic3D | Fantasia3D | ProlificDreamer | X-Dreamer |
 |
 |
 |
 |
 |
 |
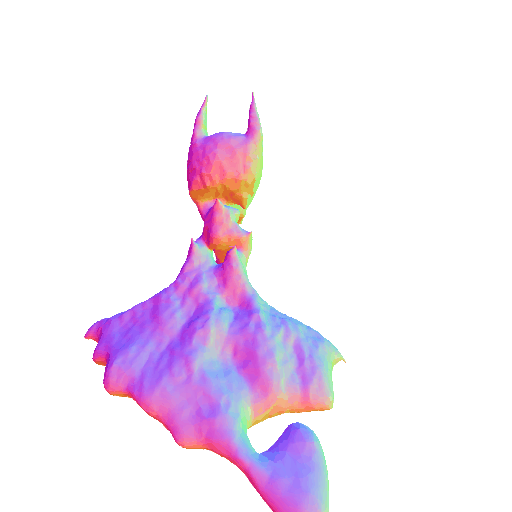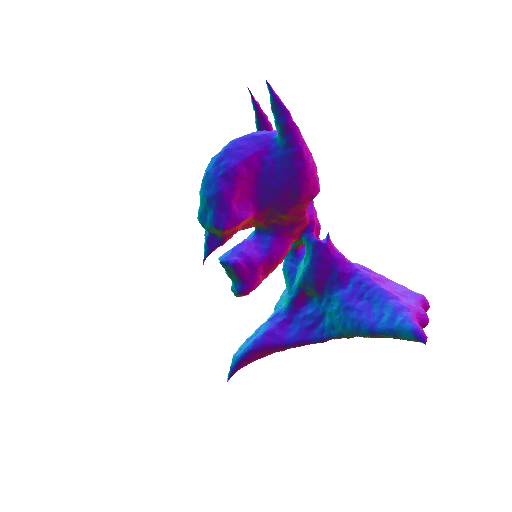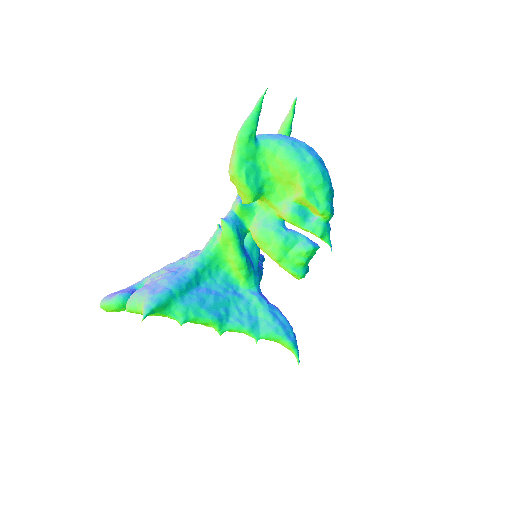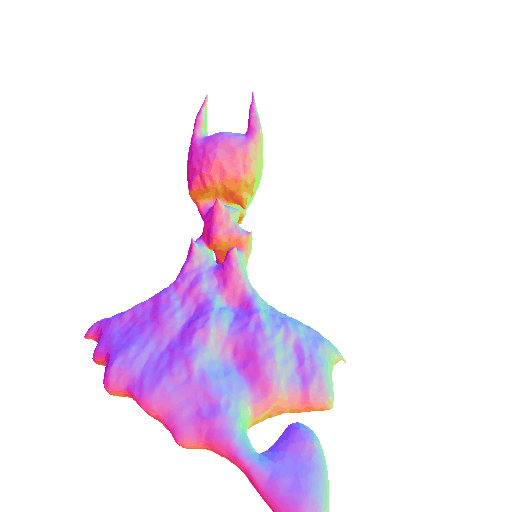 |
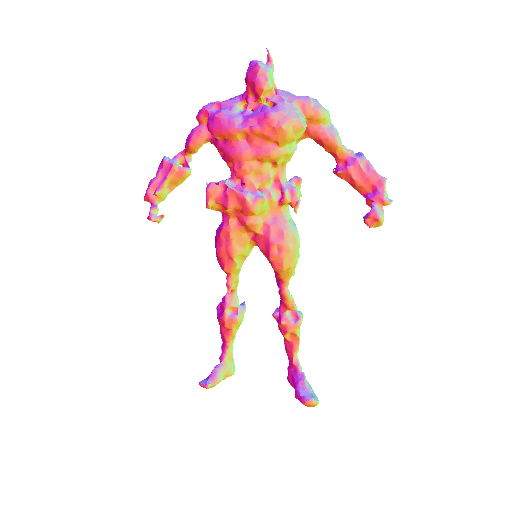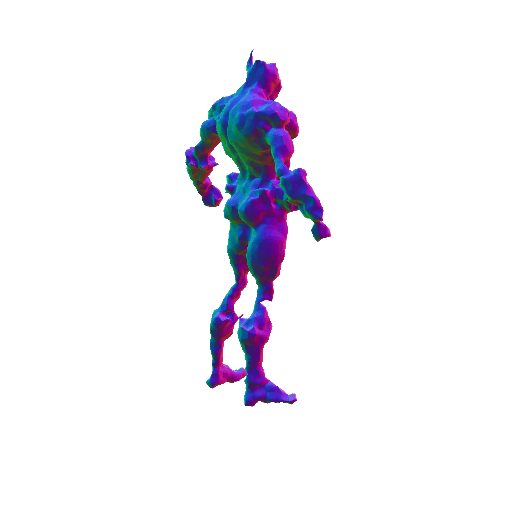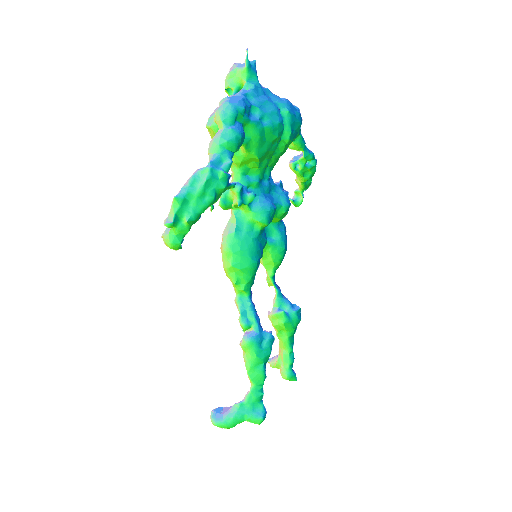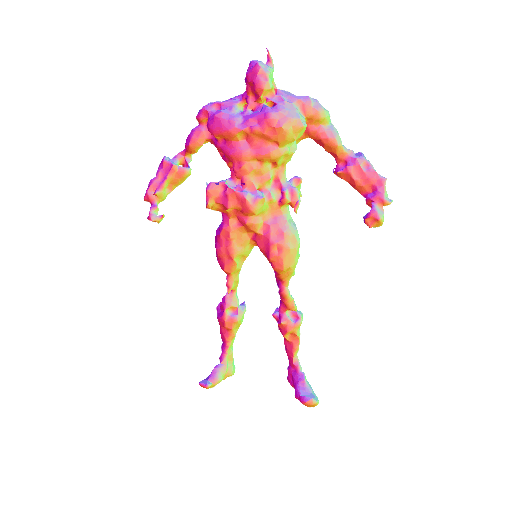 |
 |
 |
| A 3D rendering of Batman, highly detailed. | ||||
 |
 |
 |
 |
 |
 |
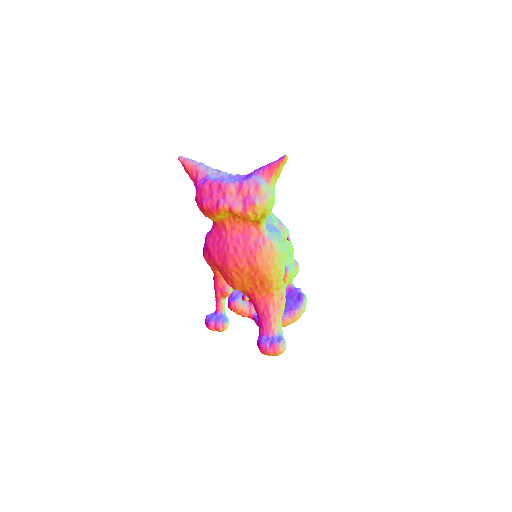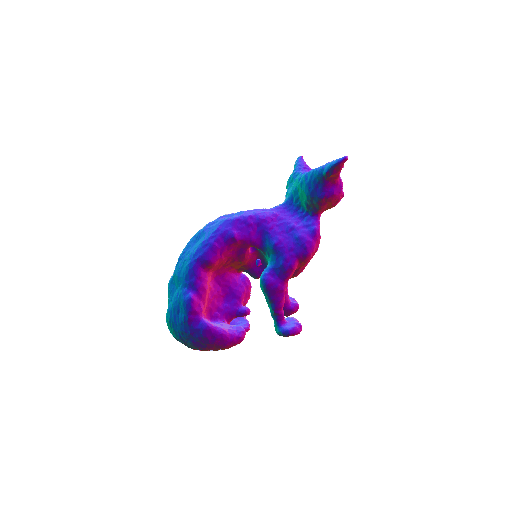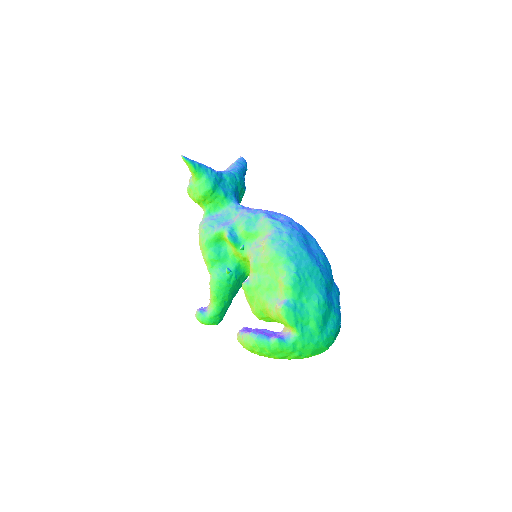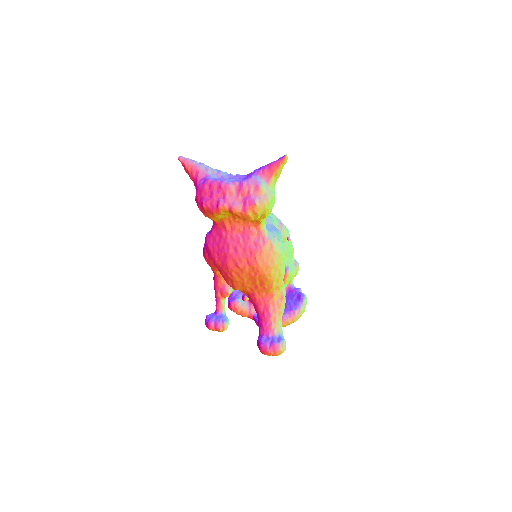 |
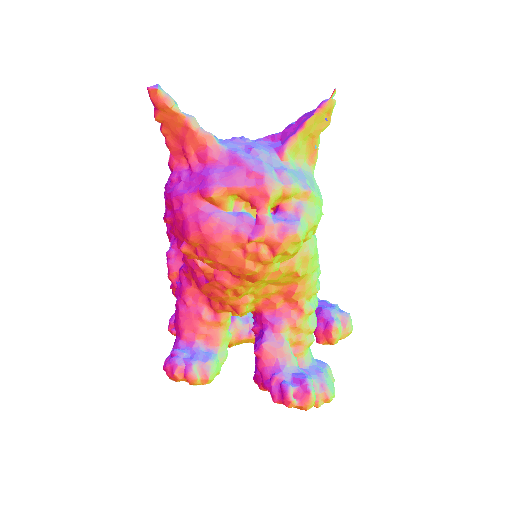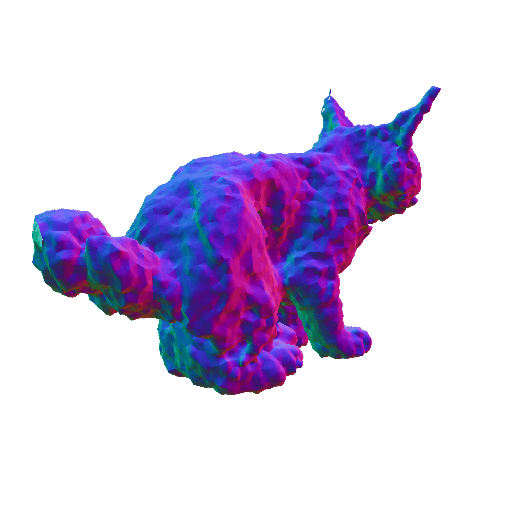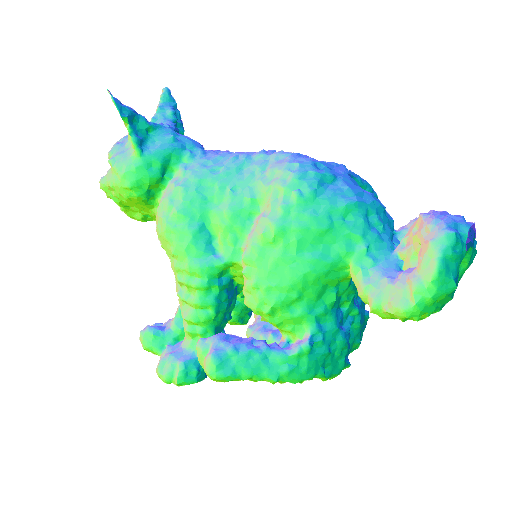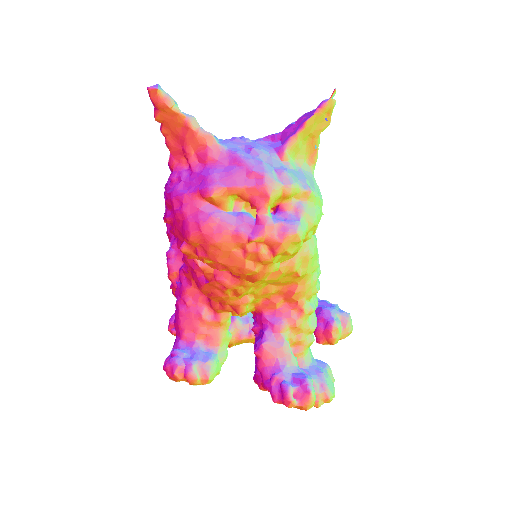 |
 |
 |
| A cat, highly detailed. | ||||
 |
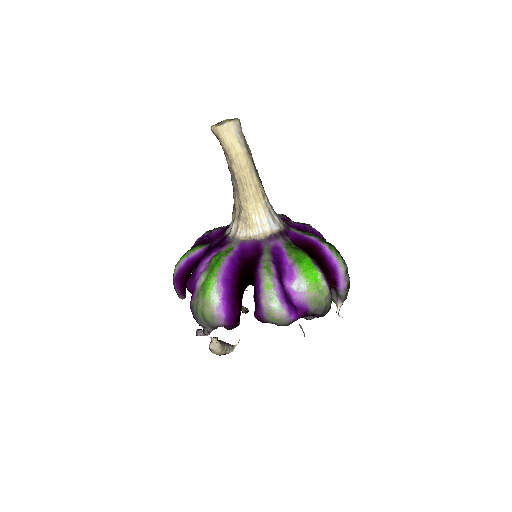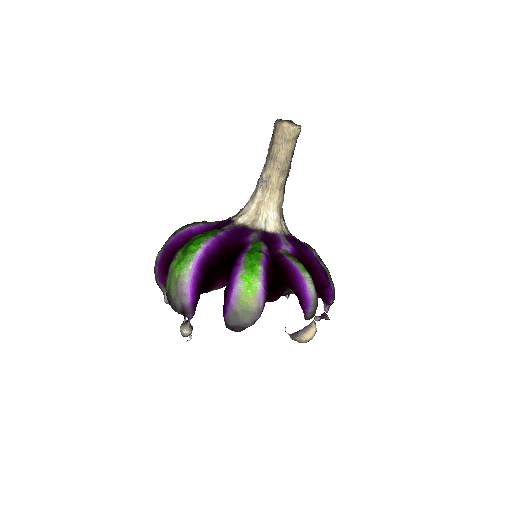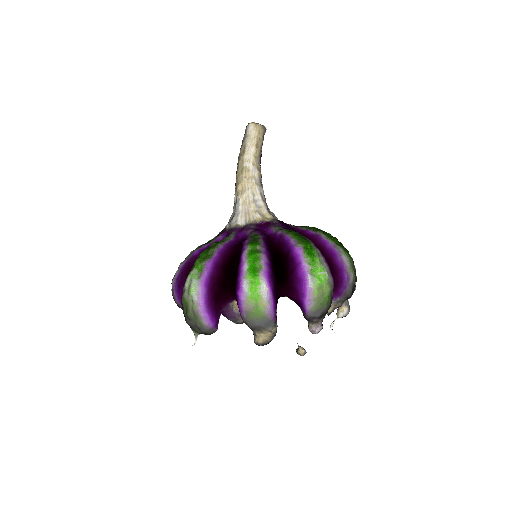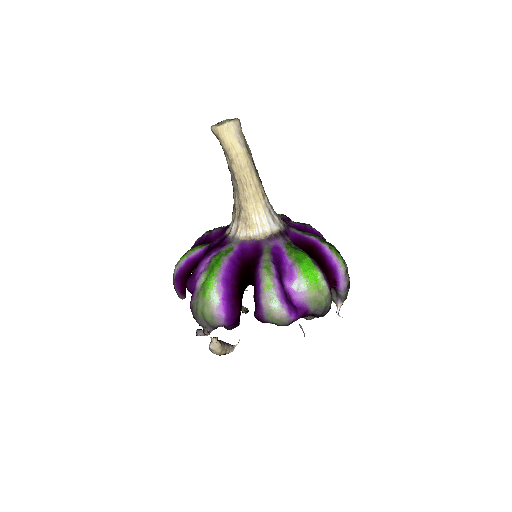 |
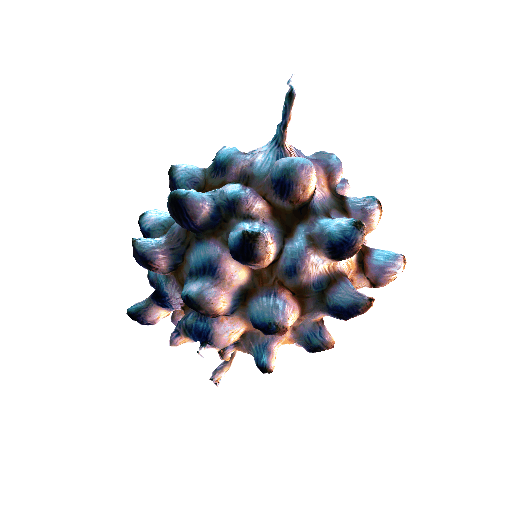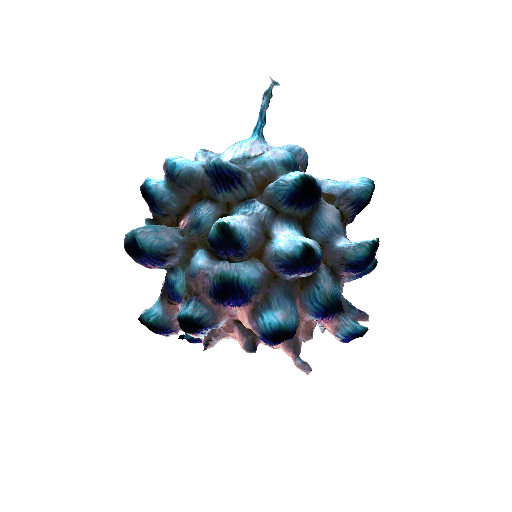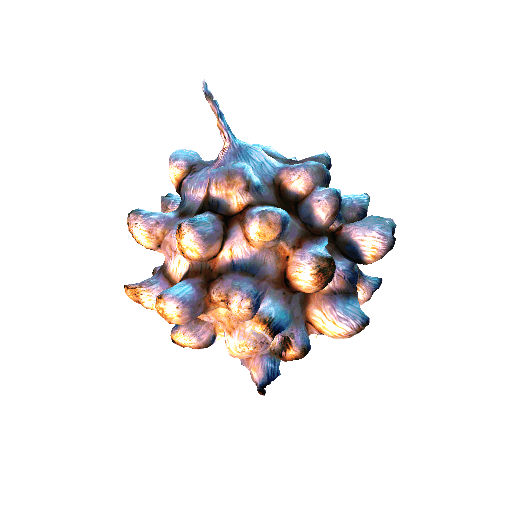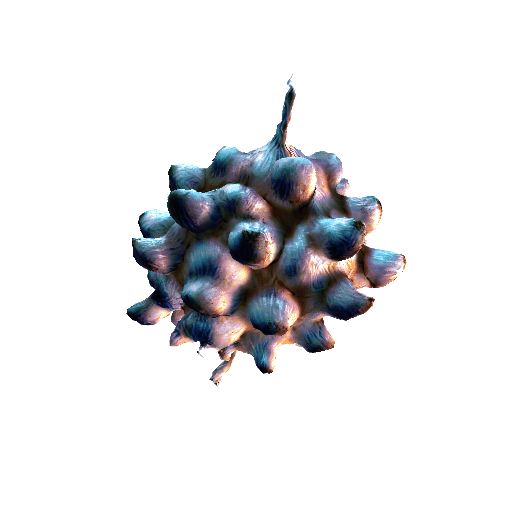 |
 |
 |
 |
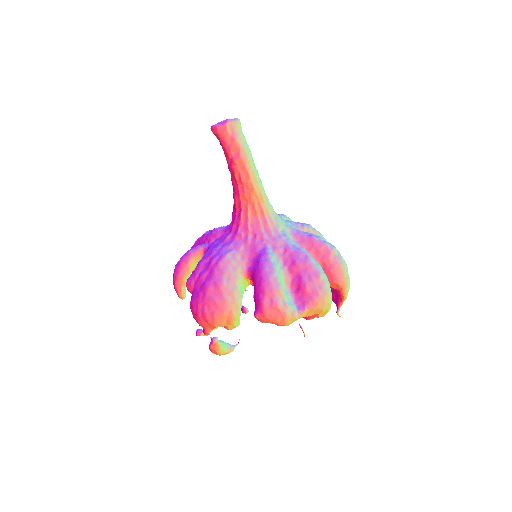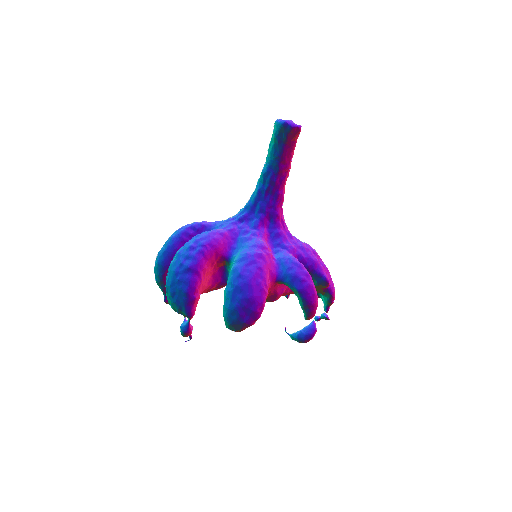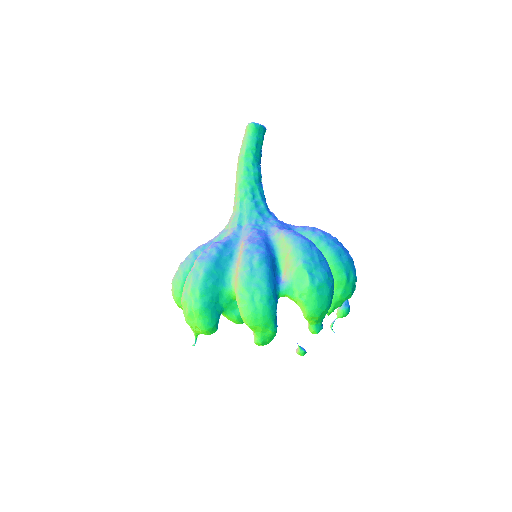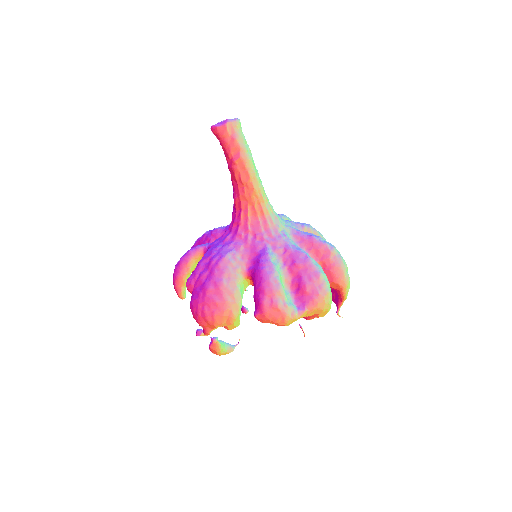 |
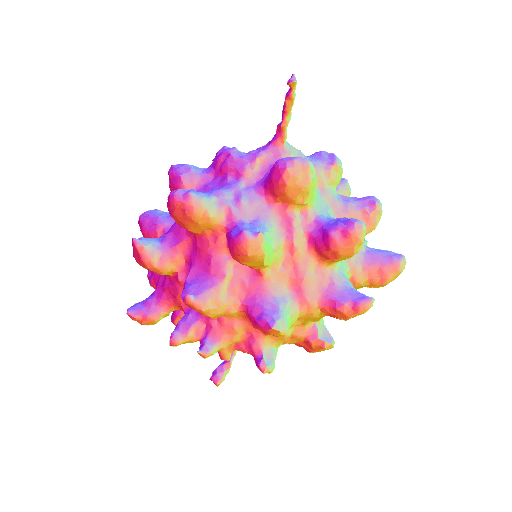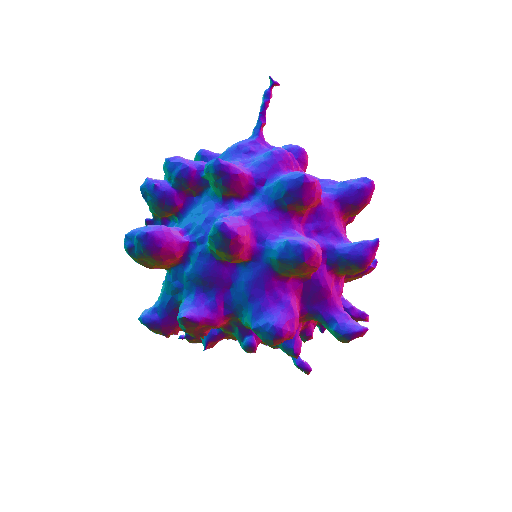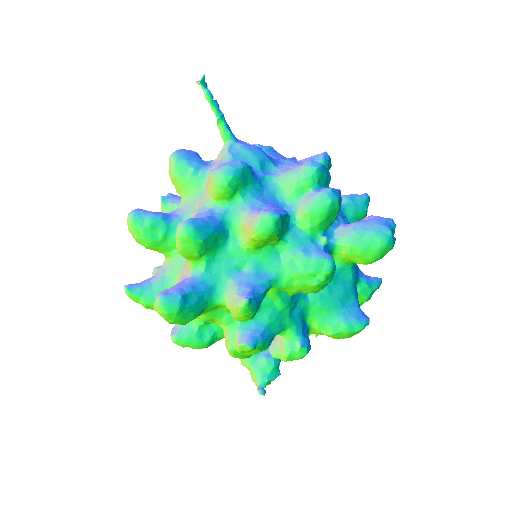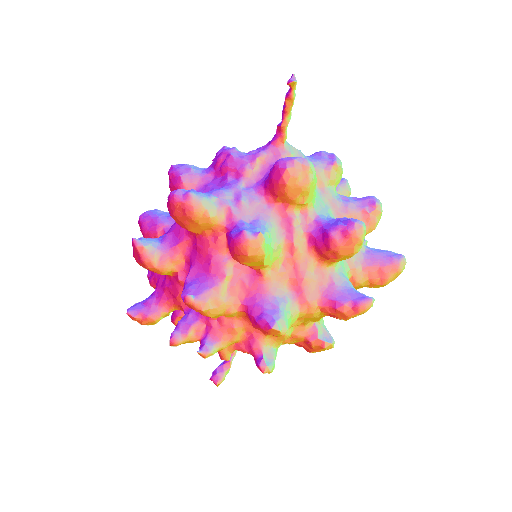 |
 |
 |
| Garlic with white skin, highly detailed, 8K, HD. | ||||
 |
 |
 |
 |
 |
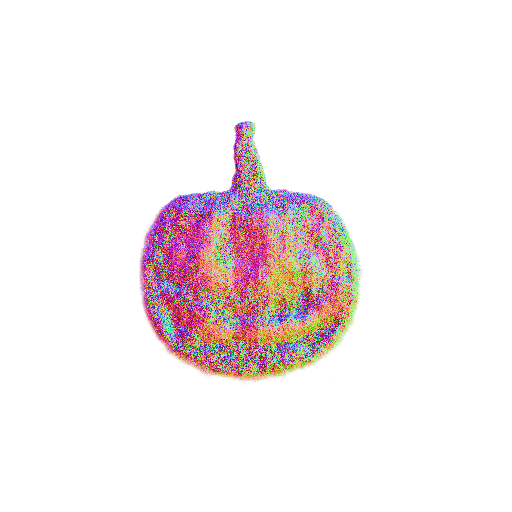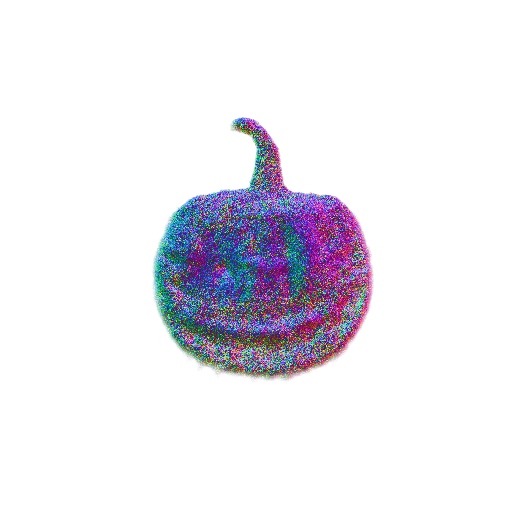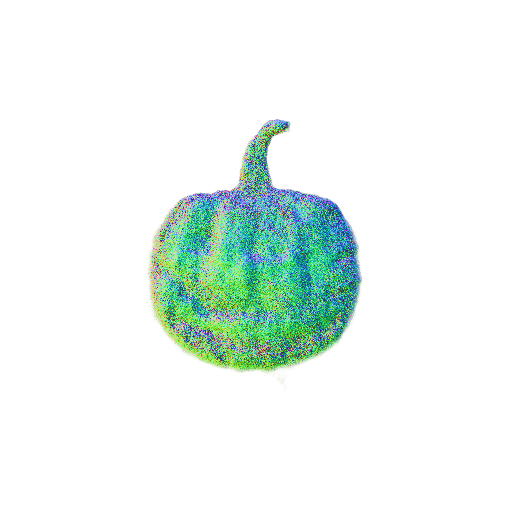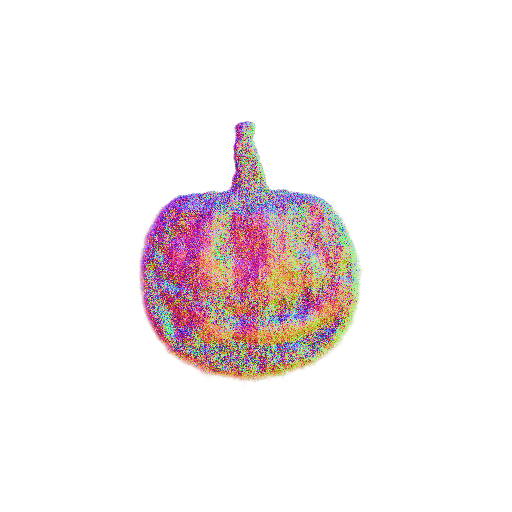 |
 |
 |
 |
 |
| A pumpkin, highly detailed, 8K, HD. | ||||
 |
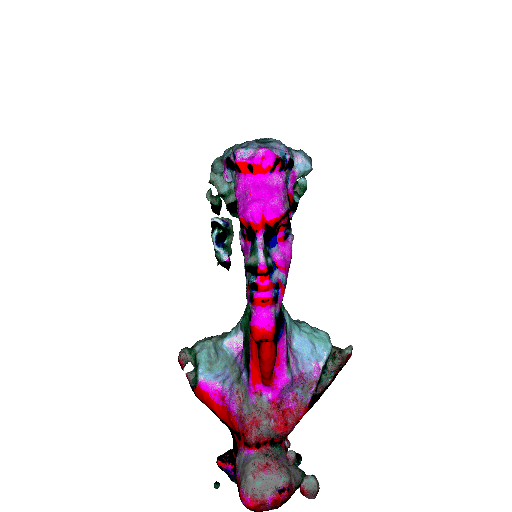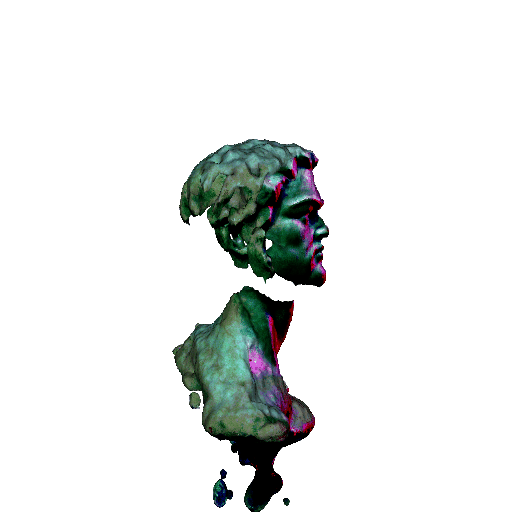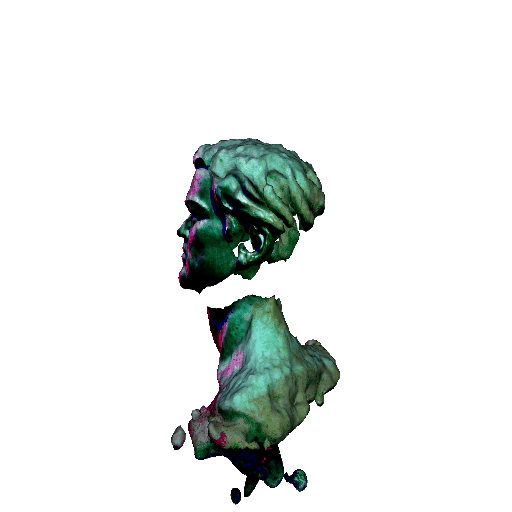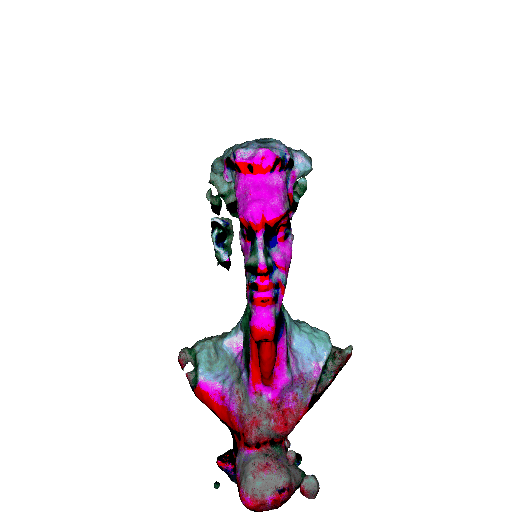 |
 |
 |
 |
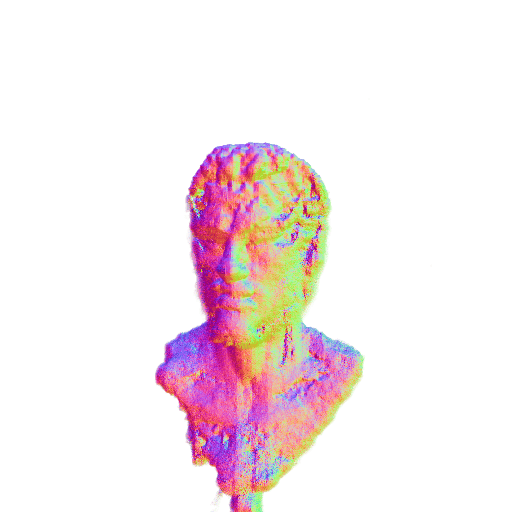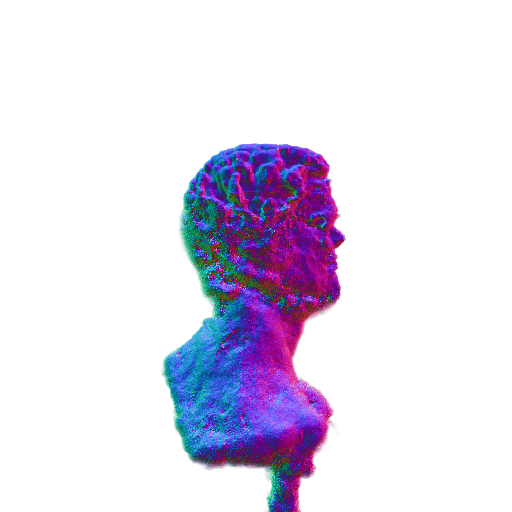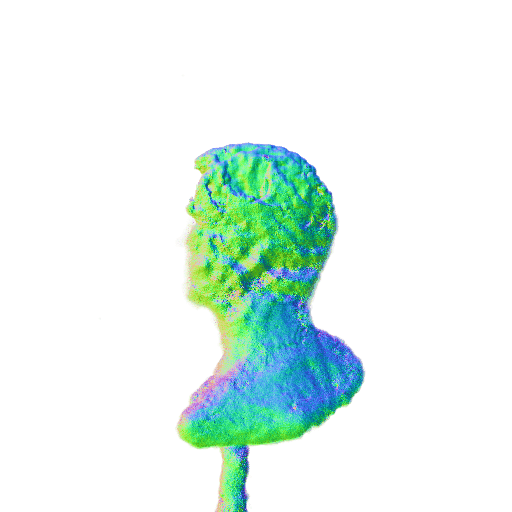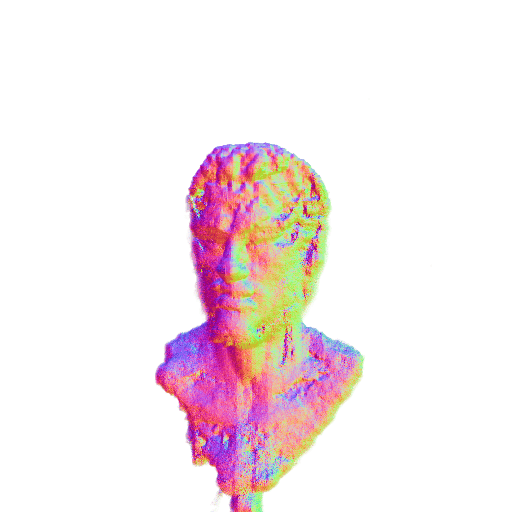 |
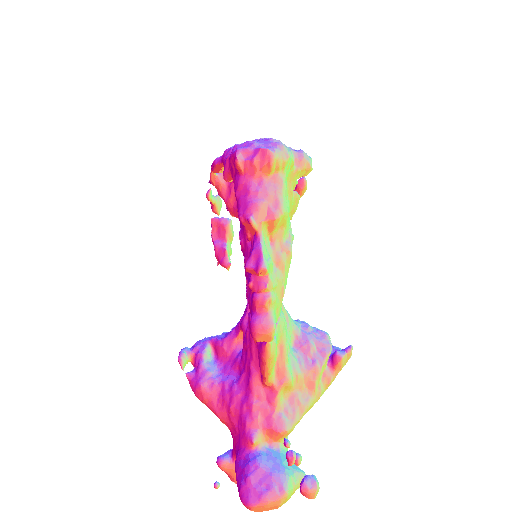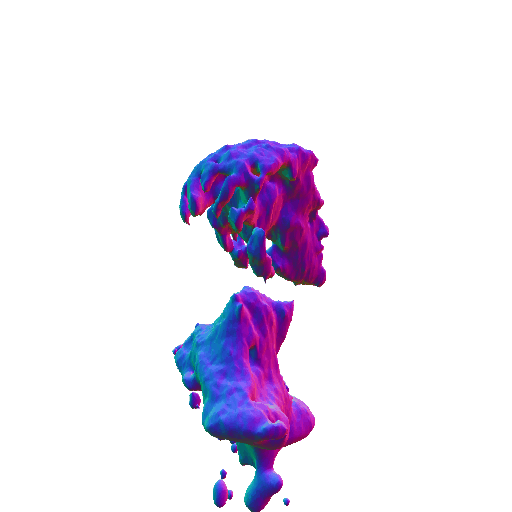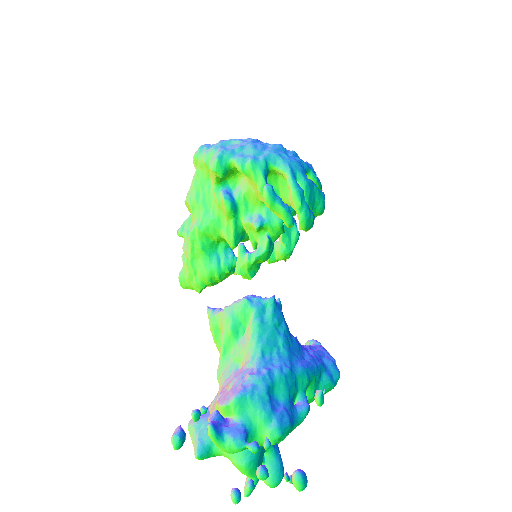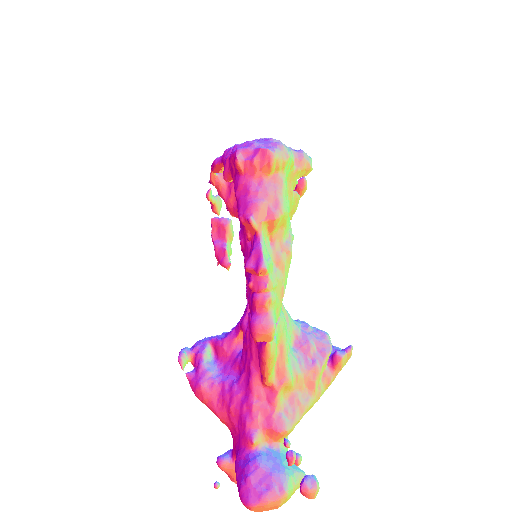 |
 |
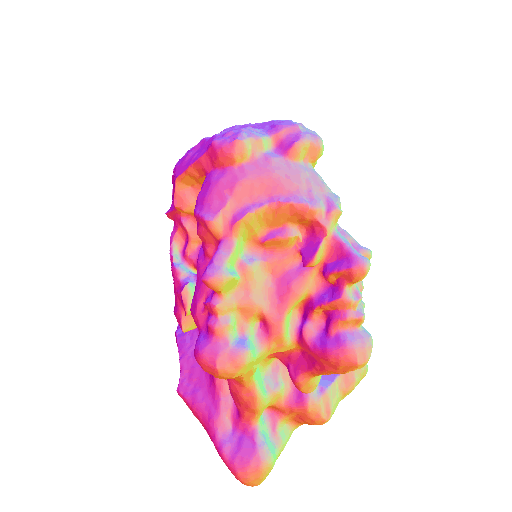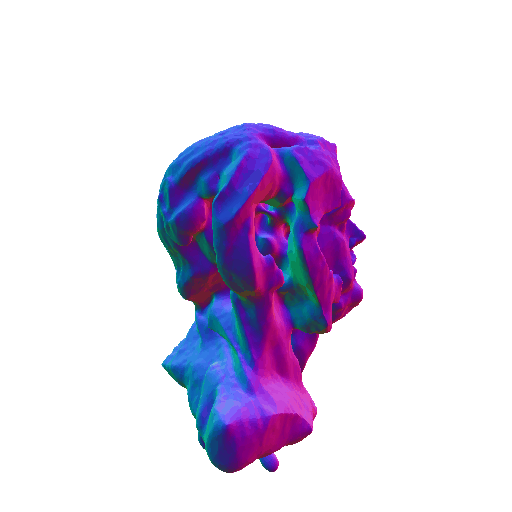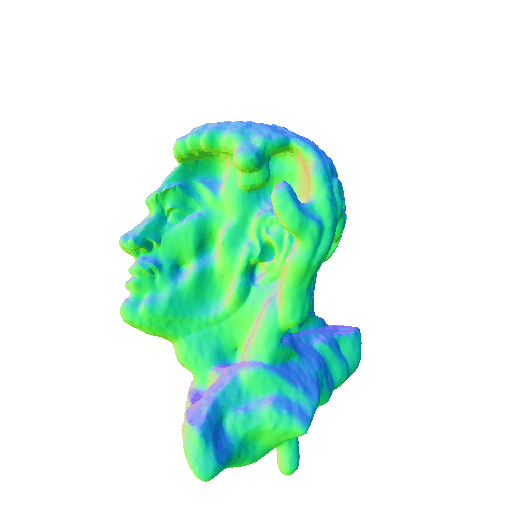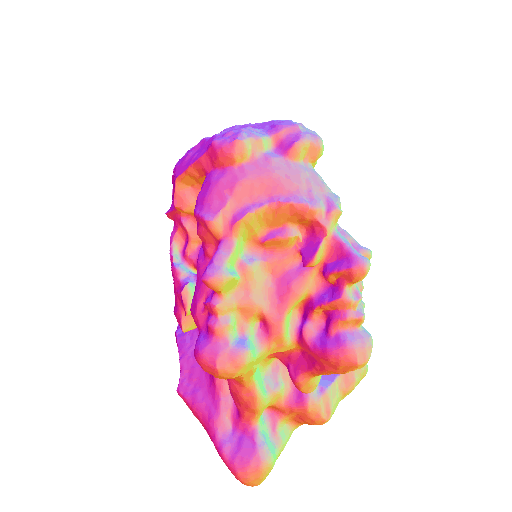 |
 |
| A statue of Leonardo DiCaprio's head. | ||||
 |
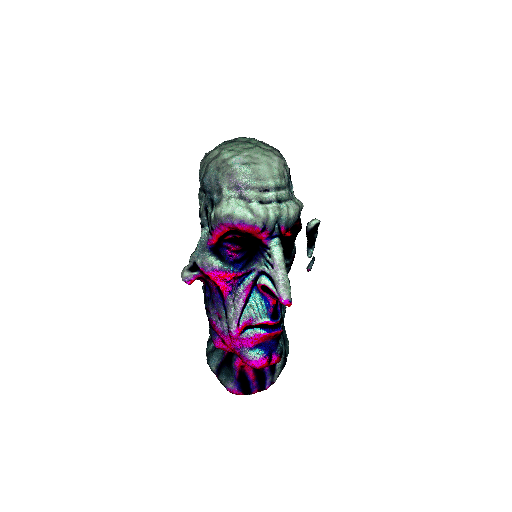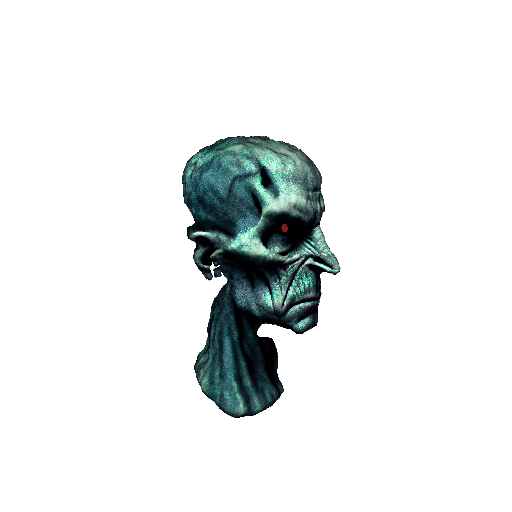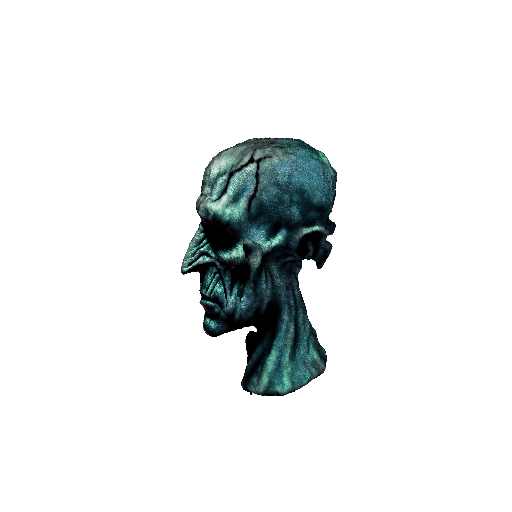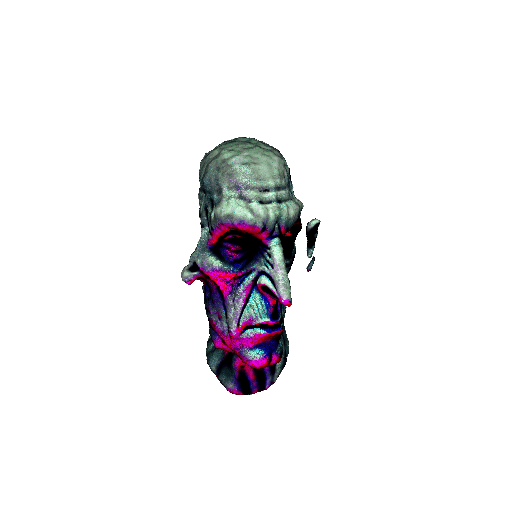 |
 |
 |
 |
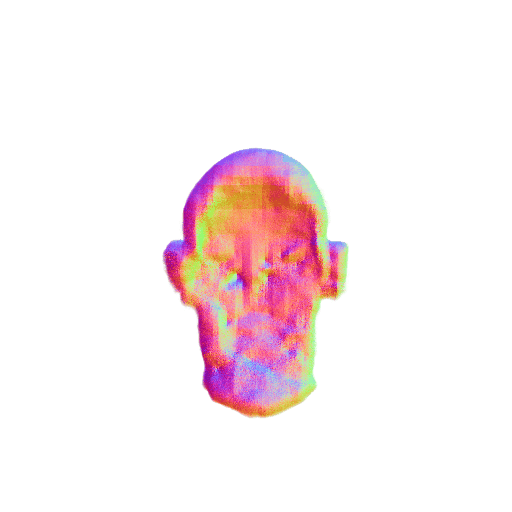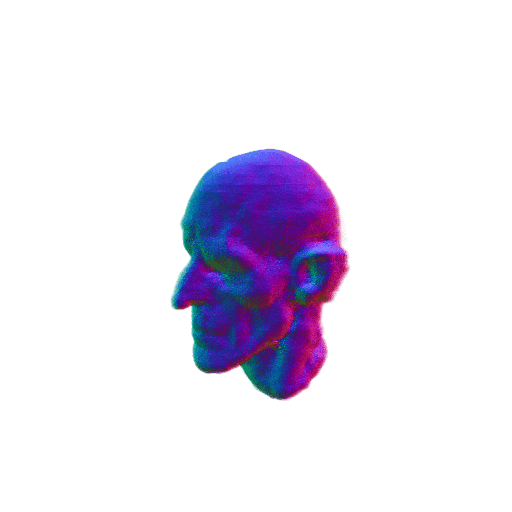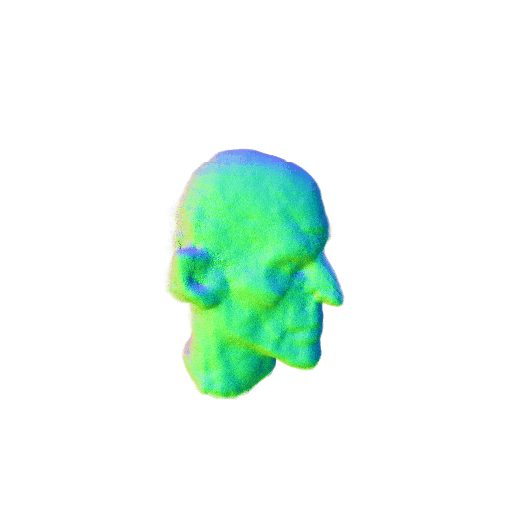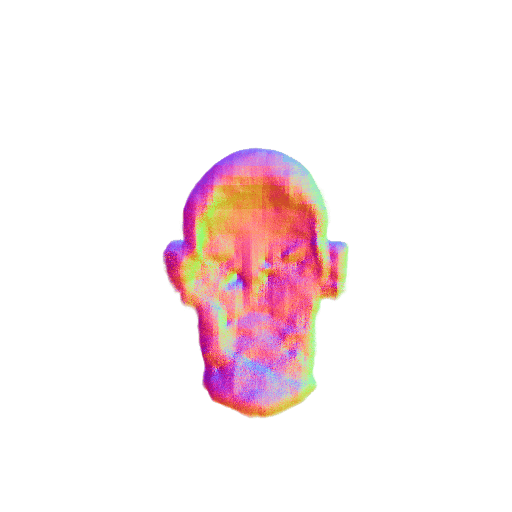 |
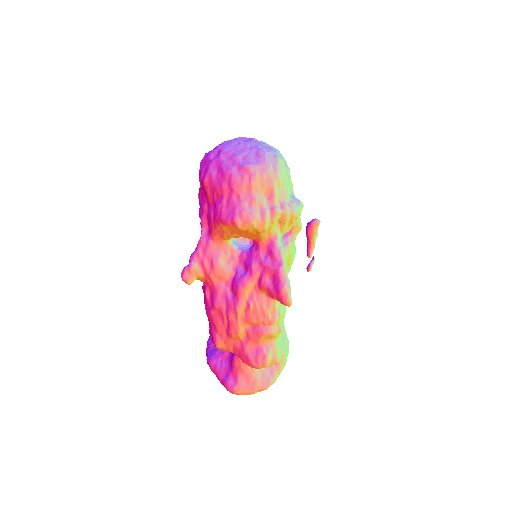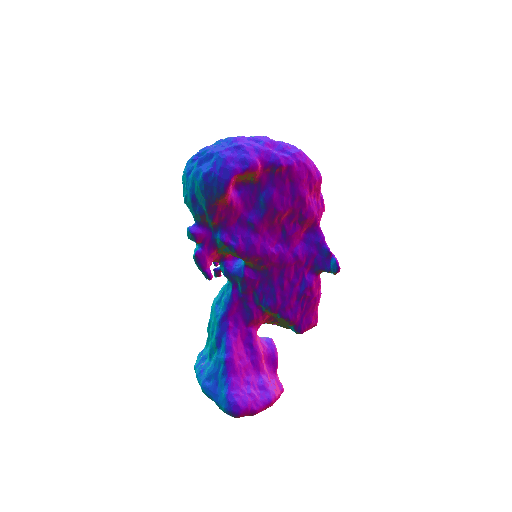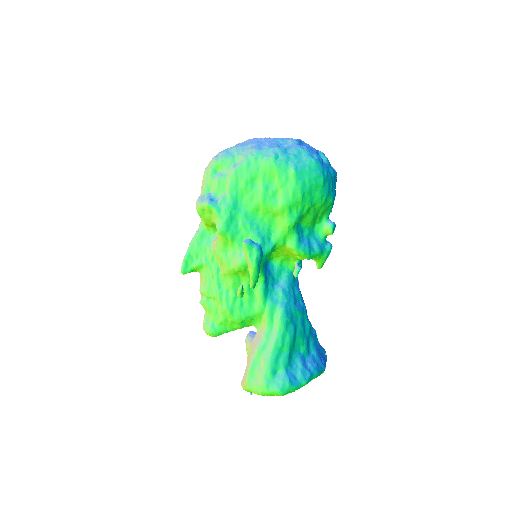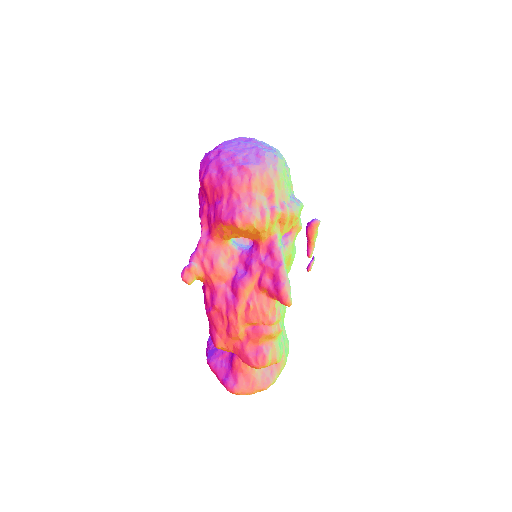 |
 |
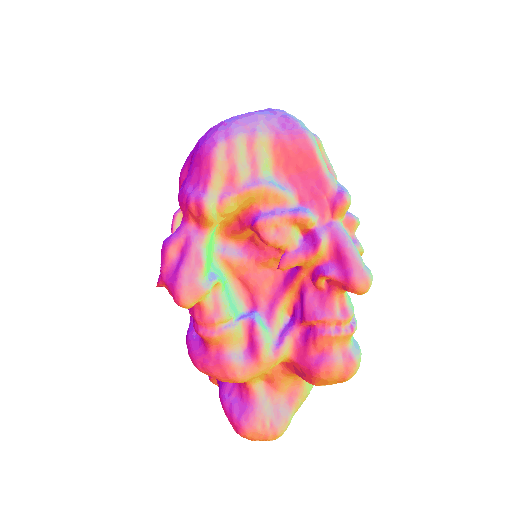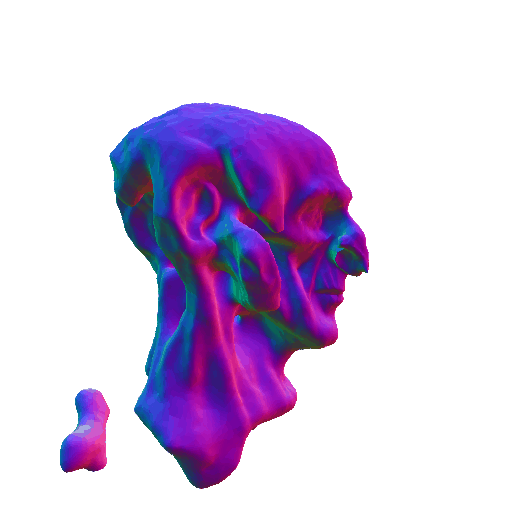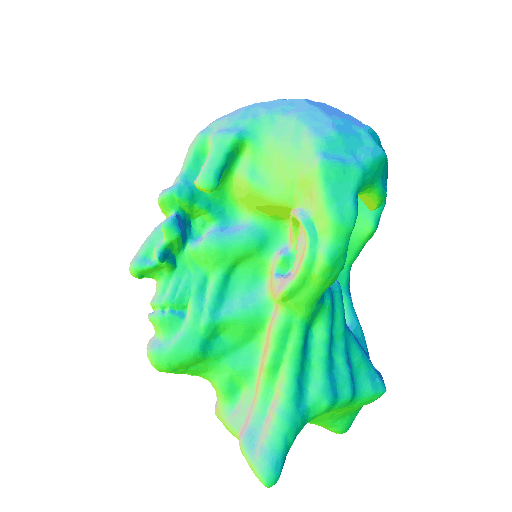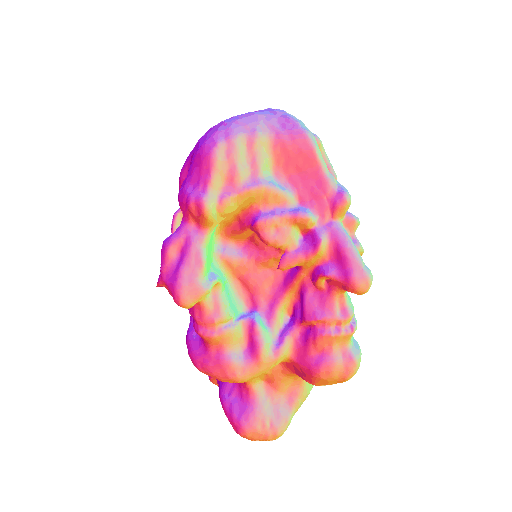 |
 |
| A DSLR photo of Lord Voldemort's head, highly detailed. | ||||